Zero 1-to-3: differenze tra le versioni
Nessun oggetto della modifica |
Nessun oggetto della modifica |
||
| Riga 1: | Riga 1: | ||
Modello creato dal Columbia University Computer Vision Lab che permette di visualizzare le immagini in altre pose, rendendole quindi a tutti gli effetti 3D. | Modello creato dal Columbia University Computer Vision Lab che permette di visualizzare le immagini in altre pose, rendendole quindi a tutti gli effetti 3D. | ||
Può essere usato in | [https://zero123.cs.columbia.edu/assets/teaser.png esempio dell'effetto] | ||
Può essere usato in [https://github.com/lllyasviel/stable-diffusion-webui-forge?tab=readme-ov-file Stable Diffusion WebUI]. | |||
== Links == | == Links == | ||
[https://zero123.cs.columbia.edu Homepage del progetto] | [https://zero123.cs.columbia.edu Homepage del progetto] | ||
[https://huggingface.co/cvlab Link su HuggingFace] | [https://huggingface.co/cvlab Link su HuggingFace] | ||
Versione delle 19:10, 3 mar 2024
Modello creato dal Columbia University Computer Vision Lab che permette di visualizzare le immagini in altre pose, rendendole quindi a tutti gli effetti 3D.
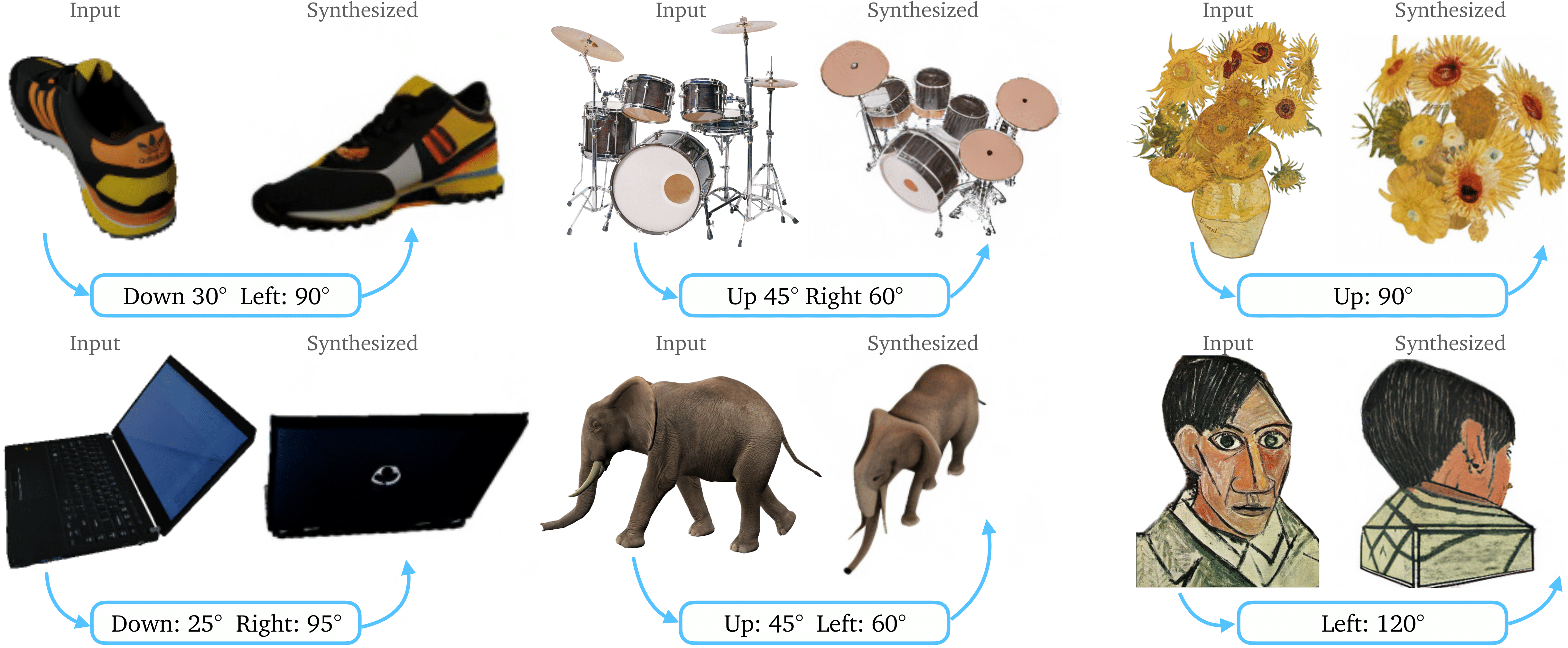{kind=link}
Può essere usato in Stable Diffusion WebUI.